A Class on Predicting FM Radio Signals
Nick’s Signal Spot is a new feature in which Nick Langan explores RF signals, propagation, new equipment and related endeavors.
At Villanova University, I teach an undergraduate Computer Science course, Platform-Based Computing (CSC 2053).
It is a fun class and one I feel fortunate to be able to instruct. The first half covers web and mobile application development, which for at least many of the students is their first time building applications. The second half then takes my students through many of the cool things they can do with the Python programming language.
Python is well-known in the data science community for its adaptability to large datasets, breaking them down statistically and gathering potential trends, and then, in some cases, to make predictions.
My 16 students by now are probably good and tired of looking at radio station data — but I jumped at the chance to use real-world data that I’ve gathered for my RadioLand app project.
After a few weeks of using Python libraries to make some general observations on radio stations in a given state that they chose, I wanted to see if we could come up with a way to predict the signal strengths, or field strengths, of FM stations, numerically.
Machine learning is a way to train software, known as a model, to make predictions using data.
The data generated by the time-tested Longley-Rice propagation model, still relied upon by the FCC and many others and used within my RadioLand app, would work as the perfect training dataset for the class.
The study
A course on machine learning itself could easily span a whole semester. For me, I only had one two-and-a-half-hour class to explore it with the group and some of that time was devoted to their ongoing semester-long projects.
So, the most practical approach was to explore the use of a common first-time machine learning tactic: predicting through linear regression.
In its most basic form, linear regression is a technique that finds a relationship between statistical variables. In the context of our lab, we wanted to find which statistics have the strongest relationship to predict an FM station’s field strength.
I extracted out of my RadioLand server pre-calculated Longley-Rice data for 25 random locations across the United States, with the signals measured in dBuV/m.
You can see a map of those locations below.
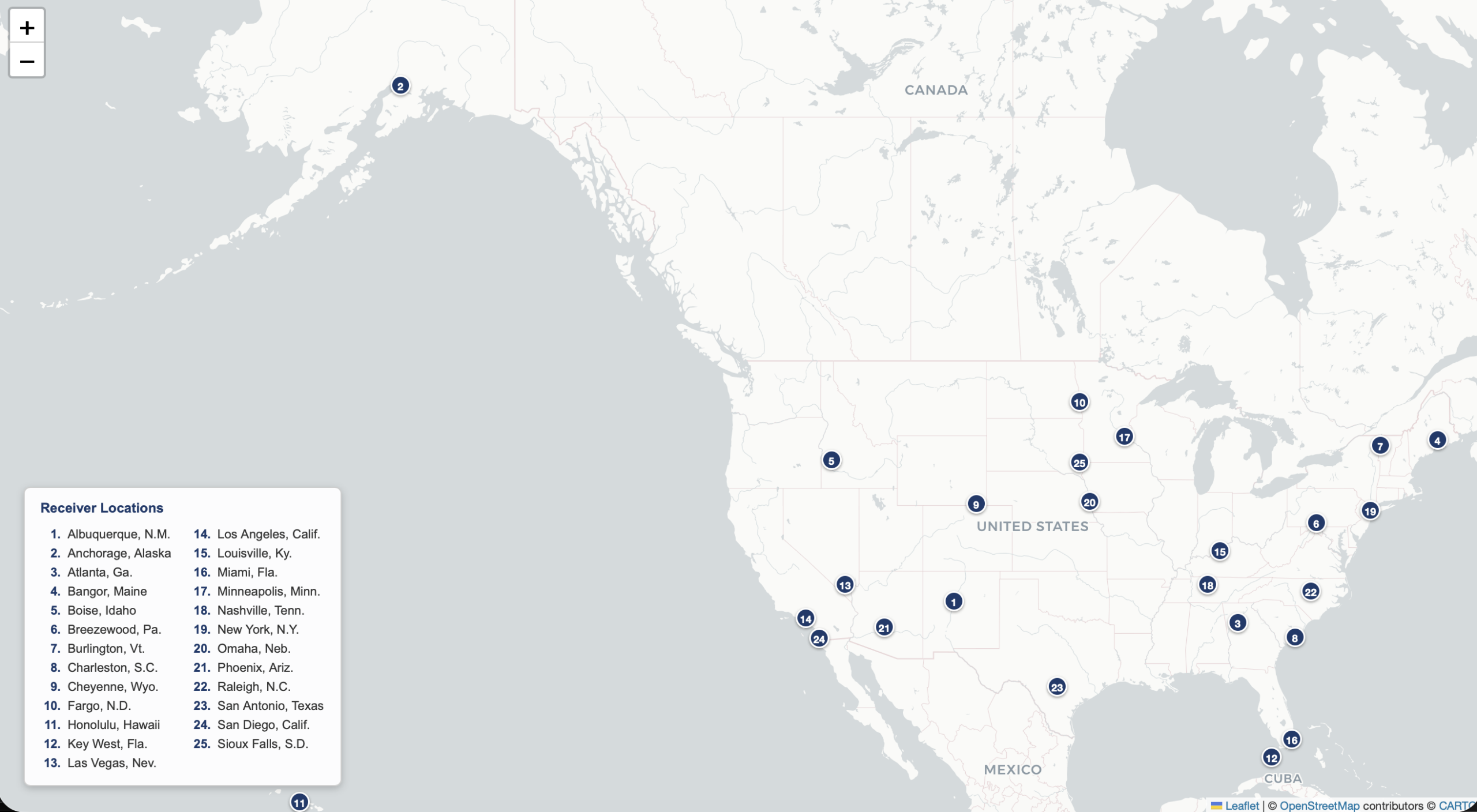
For each location, we had all FM stations available that Longley-Rice predicted to have field strengths of at least 40 dBuV/m. Then, we also had each station’s callsign, frequency, city, state, transmitting effective radiated power, antenna height above average terrain and the distance from our “receiver” location.
80/20 rule
First, I had the students run through typical machine learning techniques, which include splitting our 25-city data into “test” and “training” datasets.
The training data — or 80% of it — is used to train our linear regression model.
The test data — or the remaining 20% — is used to test the model to see how accurately it performs. The logic behind it is akin to knowing the answers to a test ahead of time.
That’s something my students can appreciate!
A model can perform well on the data it knows, but what happens when we throw it curveballs?
This all might sound complicated, but Python’s scikit-learn library has a linear regression model built right in. With programming syntax under our belt, it’s more a matter of feeding it the data and analyzing its performance.
Distance-first approach
With just a rudimentary understanding of signal propagation, you can probably discern that the most logical place to start for testing a feature’s relationship to predicting the strength of a radio signal is the distance from the transmitter.
The farther you are away from the source, the weaker it ought to be.
So that’s where we started. Could distance alone be a reliable predictor of a station’s field strength?
With our regression model, we use a metric called the R-squared score to understand its performance. Depending on the situation, it’s a quick and easy way to score the effectiveness of the relationship between our features and what we are trying to predict.
An R-squared score of 1 is a perfect score. A score of 0.5 would mean our feature explains half of the variance that is possible with our target. In some cases that might be OK.
But with field strength, we wanted to aim for something higher.
In our first go-around just using the distance, it resulted in an R-squared score of 0.48.
Scikit-learn also provides us with the root mean squared error, which gives us the average magnitude of error between the predicted and actual values in the exact same units we are trying to measure — dBuV/m. For our first regression model, it was about 16 dBuV/m.
That could be the difference between predicting a comfortably strong signal from a signal off the Empire State Building in New York City — at a level of 70 dBuV/m — and a fringe-type signal at around 55 dBuV/m.
While there is indeed a relationship between distance and field strength, it is not strong enough on its own.
With a model, we can combine the predictive features. What happened if we added a station’s transmitting power, antenna height and frequency to the mix?
Our R-squared score improved to 0.74.
Distance has the strongest correlation, but second is ERP. Antenna height above average terrain and the station’s frequency itself showed a very weak relationship.
Fitting a line
You do not have to be a mathematical maven to explore computer programming or machine learning. But in some cases, a little know-how helps.
Linear regression is based on how well your predictive data fits along a straight line.
But radio signals follow the inverse-square law, which states that intensity is inversely proportional to the square of the distance from a source.
To engineer a feature that accounts for this, we have to address the non-linear relationship. A common and highly effective tactic in machine learning to “fit” non-linear data around a straight line is to take the logarithmic value of a feature — in this case, distance.
We added the log of the distance as well as the log of ERP, as that feature also has a non-linear relationship with the field strength.
The result? An R-squared score of 0.89, or a mean error of 7.5 dBuV/m.
What’s missing?
Then I asked each of the students, in their lab workbook, to analyze two of the cities in the 25-city data set to see how our linear model worked in each location in isolation. First, they were given New York City and then they could choose one of the other 25 cities.
On a map, they could compare stations that the model under-predicted, over-predicted or placed within close proximity of Longley-Rice. A green dot here is good — that means the model came within 5 dBuV/m of Longley-Rice for the same station, such as the signals on the Empire State Building, for example.
Sophomore student Anthony Dell’Avvocato pointed out that many of the over-predicted signals from a theoretical receiver in New York were in the direction of northern New Jersey.
Many of my students call New Jersey home, including Dell’Avvocato, and its geography has been a theme of some of our exercises all semester long.
“The model is struggling with urban canyons, terrain blocking and signal reflections, which aren’t captured by distance, power or height alone,” he wrote.
I finally asked each student if they were a broadcast engineer, would they find this model valuable?
Freshman Alan Uribe identified that although the Longley-Rice data it was trained on accounts for terrain, our linear model has no feature that does the same.
“It’s useful for early planning but not accurate enough for final decisions,” he said.
Sophomore Jack Behringer noted that for flatter areas, our regression model might prove useful. But in an area like California, he said, it would be thwarted by terrain.
“A real broadcast engineer knows the terrain and population of the area — this is overlooked by the model,” freshman Erin Campbell noted.
Takeaways
I don’t think anyone would comfortably rely on the model we came up with in one class to make real-world decisions. But the world of machine learning offers many more possibilities.
My research student, senior Minh Bigting, used a gradient boost model on similar data and has come up with promising results.
All in all, it was a fun way to show my group of students how FM signals travel and why there are a number of factors involved with hearing a station.
Comment on this or any article. Email radioworld@futurenet.com.
The post A Class on Predicting FM Radio Signals appeared first on Radio World.